КомпьютерПресс №3 1991. И. Липкин.
Архитектура микропроцессоров
 В этом выпуске Вы продолжите знакомство с системой прерываний процессора i286, а также
с некоторыми устройствами, помогающими центральному процессору успешно справляться со
своими проблемами.
В этом выпуске Вы продолжите знакомство с системой прерываний процессора i286, а также
с некоторыми устройствами, помогающими центральному процессору успешно справляться со
своими проблемами.
Приоритеты
В предыдущем выпуске шла речь о прерываниях. Мы выяснили, что безусловным авторитетом для процессора является сигнал о неминуемой катастрофе, попадающий на вход NMI. А вот как быть с прерываниями, если у входа INTR «стучатся» сразу два–три устройства, и флажок IF равен единице, то есть процессор обязан как-то на это реагировать? Одновременная обработка нескольких прерываний – задача непосильная для i286, да и бессмысленная, значит процессору придется каким-то образом отвечать на поступившие сигналы по очереди.
Мы уже вскользь говорили о возможности разграничения прерываний по степени их важности, то есть, о работе системы прерываний с иерархической структурой, и кстати упомянули, что для процессора 80286 этот режим не предусмотрен.
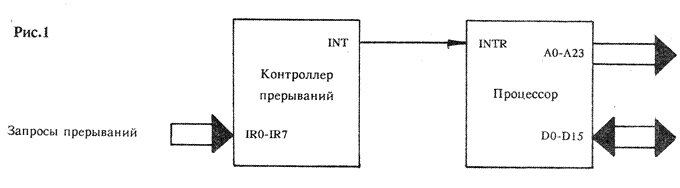
В самом простом случае каждому устройству, входящему в систему, присваивается свой уникальный уровень приоритета, а все шины прерываний подключаются к контроллеру (рис.1). Теперь, если, к примеру, два прерывания возникнут одновременно, контроллер отдаст предпочтение сигналу от устройства с наивысшим приоритетом, а второе прерывание запомнит и выдаст его на вход INTR только после окончания процедуры обработки первого прерывания.
{kind=link}
Но вот происходит ситуация, которая требует специального механизма для своего разрешения: я имею в виду возникновение сигнала прерывания более высокого приоритета в то время, когда процессор занят обработкой менее «значимого» прерывания. Здесь всё будет зависеть от состояния флажка разрешения прерываний. Если IF = 1‚ текущая процедура обработки останавливается, и запускается процедура обработки прерывания с более высоким приоритетом. В том же случае, когда IF = 0, процессор, как ему и положено, на «звонки» не откликается, сколь бы высок не был приоритет у назойливого просителя.
Уровень приоритета назначается, в основном, из соображений, имеющих отношение к конструктивным особенностям, а также к быстродействию соответствующих устройств. Особенно наглядно это можно пояснить на примере сравнения работы стримера (накопителя на магнитной ленте) и жесткого диска. Если стример устройство само по себе достаточно медленное – функционирует в старт/стопном режиме, и «вклинивание» чужого прерывания в момент записи или считывания информации практически не влияет на его производительность, то жесткий диск не имеет возможности мгновенно «замереть» в случае прерывания и потом «отмереть», когда процедура обработки прерывания завершится. Он продолжает вращаться с постоянной скоростью, и в момент возврата из процедуры прерывания под его головками совсем не обязательно будет нужный сектор. Отсюда очевидно, что дисковый накопитель необходимо наградить более высоким приоритетом, чем стример или клавиатуру. Кстати, о клавиатуре: пользователь вообще не заметит, если символ на экране монитора задержится на пару миллисекунд.
Системная синхронизация
Как Вы знаете, внутренняя адресная шина i286 – 16–разрядная, а виртуальный адрес выражается 24-битным числом. Налицо, как говорят парламентарии, явное противоречие. Так ли это?
Если посмотреть на процессор снаружи (с точки зрения периферийных устройств), то можно заметить, что он соединен с внешним миром посредством шины, состоящей из трех групп проводников (рис.2). Одну из групп составляет адресная шина, состоящая из 24 линий (A0-A23). Таким образом, физический адрес, будь то в реальном или в виртуальном режиме, не превышает ширины внешней шины адреса. Во вторую группу входят 16 линий шины данных (D0-D15), все остальное приходится на шину управления. Сюда входят линии состояния процессора, линия запроса прерывания и т.д.
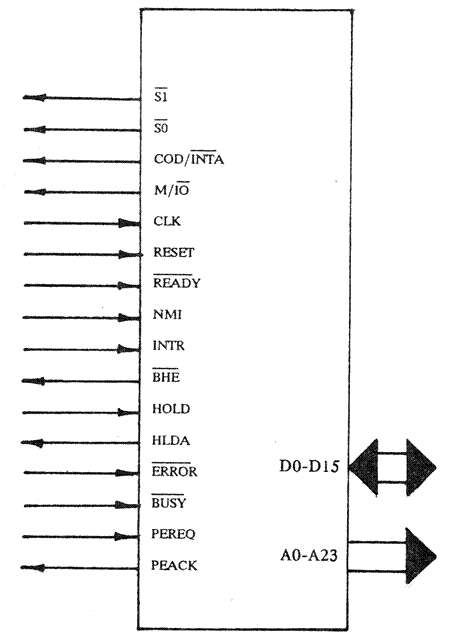
Все устройства управления внешними устройствами – контроллеры – также подключены к шине, причем если контроллеру дисков или видеоадаптеру отводятся фиксированные адреса, то оперативная память, являющаяся внешним по отношению к процессору устройством, имеет целый диапазон адресов. По линиям данных от периферии к процессору и обратно передаются коды команд и данные. Для того чтобы вся эта система заработала, необходимо, чтобы внешние устройства и процессор точно знали, в какие моменты времени будет происходить передача данных по шине, а когда ожидать получения или выдачи адреса. Контроллеры, ОЗУ и процессор могут работать с различной скоростью, а в таком случае невозможно заставить входящие в систему устройства «понимать» друг друга.
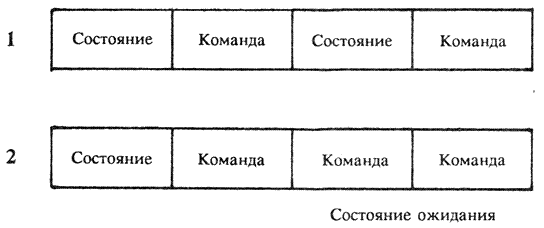
Избежать подобной неразберихи помогает системная синхронизация. Специальная микросхема, называемая генератором синхронизации, вырабатывает импульсы определенной для каждого компьютера частоты, называемые тактами. Несколько тактов составляют так называемый цикл процессора. В истории развития вычислительной техники известны различные сочетания между тактами и циклами, например, у средних ЭВМ недалекого прошлого один цикл процессора состоял из четырех тактов. В нашем случае это число вдвое меньше, то есть равно двум. Первый такт цикла называется фазой 1, а второй – фазой 2. В свою очередь, полный цикл шины в два раза длиннее цикла процессора и равен четырем тактам (рис.3). Что же происходит в системе в течение двух циклов процессора?
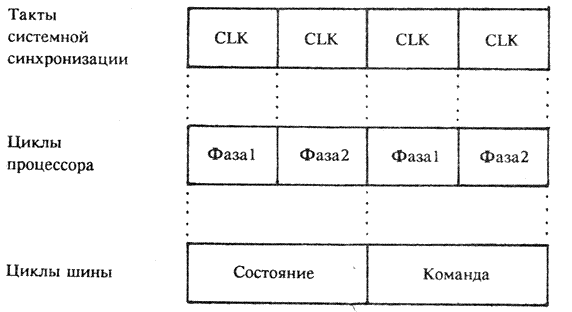
В течение первых двух тактов процессор выдает на линии состояния информацию о том, какие действия он будет производить в течение последующих двух тактов: будет ли он считывать из ОЗУ команду или данные или производить запись в оперативную память, произойдет ли прерывание или останов. В это же время на адресной шине появляется физический адрес одного из устройств или области памяти. Еще раз подчеркну, что в третьем и в четвертом тактах по линиям данных производится передача информации. Названия половинок цикла шины совпадают с их назначением: первые два такта называются циклом состояния, а вторые – командным циклом.
Все вроде бы получается хорошо: процессор командует парадом, а все устройства дружно топают в ногу, согласно указаниям капельмейстера–генератора синхронизации, но не тут-то было! Быстродействия некоторых устройств не хватает для того, чтобы завершить выполнение текущей команды перед началом нового цикла шины. Что делать? Неужели придется распрощаться с высокой тактовой частотой (для i286 это может быть 20 МГЦ) и подстраиваться к темпу работы наиболее медленного устройства? Но в этом случае теряют смысл такие быстрые операции, как пересылка данных из регистра в регистр, а ведь системные программисты знают, что использование команд типа регистр–регистр, минуя шину, ведет к очень существенному ускорению выполнения программ. Для сохранения высокой тактовой частоты было решено к общему циклу шины добавлять дополнительные командные циклы до тех пор, пока «зазевавшееся» устройство не сообщит процессору о своей готовности выполнить следующую операцию. Такие дополнительные командные циклы носят название состояния ожидания (рис.4): Для приема сигналов готовности в процессоре предусмотрен вход READY.
Подчиненный процессор
До недавнего времени в функции центрального микропроцессора не входили операции с числами в представлении с плавающей запятой. На то были свои причины, например, дороговизна соответствующего устройства, к тому же во многих приложениях сложные и интенсивные вычисления не применяются вообще. Поэтому специальная микросхема, предназначенная для операций с плавающей запятой, называемая математическим сопроцессором, как правило, является необязательным устройством и устанавливается дополнительно. Но предположим, что у Вас именно такая ситуация, когда без сопроцессора не обойтись и Вы приобрели компьютер, оборудованный микросхемой i287. Как же уживаются в одной системе, да еще на одной шине два процессора? Для начала, не следует забывать, что математический сопроцессор «не ровня» ведущему, хотя и стоит значительно дороже – основная роль в управлении системой все-таки принадлежит i286.
Теперь разберемся, каким образом процессоры узнают, когда каждому из них следует включаться в работу по перемалыванию поступающих данных. i286 спокойно проглатывает одну команду за другой до тех пор, пока не натыкается на мнемонику ESC – это означает для него, что пора к делу подключать сопроцессор. Теперь, до тех пор, пока i287 разбирается со своими вычислениями, он оповещает об этом центральный процессор сигналом BUSY. Если следующие команды не требуют подключения сопроцессора, ведущий процессор продолжает их выполнять до появления очередной команды, требующей вычислений с плавающей запятой. Только тогда i286 приходится ожидать до тех пор, пока i287 не завершит выполнение текущей команды и не освободится. Таким образом удается синхронизировать работу двух процессоров и не допустить двоевластия.
А без процессора?
Передача данных из внешнего устройства в оперативную память или наоборот происходит следующим образом: сначала процессор производит считывание слова данных (здесь 2 байта), которое, например, передал ему по шине дисковод, а затем посылает по шине то же самое слово по указанному адресу в ОЗУ. Очевидно, что для одного подобного действия потребуются два цикла шины, то есть создается впечатление, что пропускная способность шины на деле оказывается вдвое меньше ожидаемой. Существует ли возможность при передаче слова данных уложиться в один цикл шины, то есть использовать пропускную способность шины на все сто процентов? Оказывается, существует, но для этого приходится пересылать данные «в обход» ведущего процессора. Подобный способ передачи данных известен сравнительно давно и называется он прямым доступом к памяти или ПДП (Direct Memory Access – DMA).
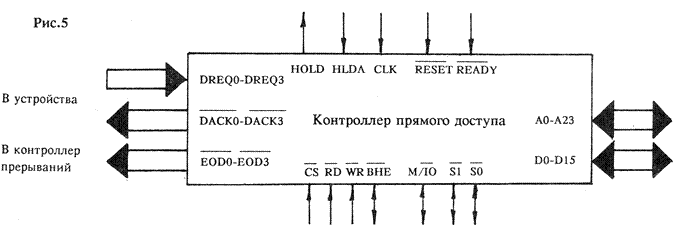
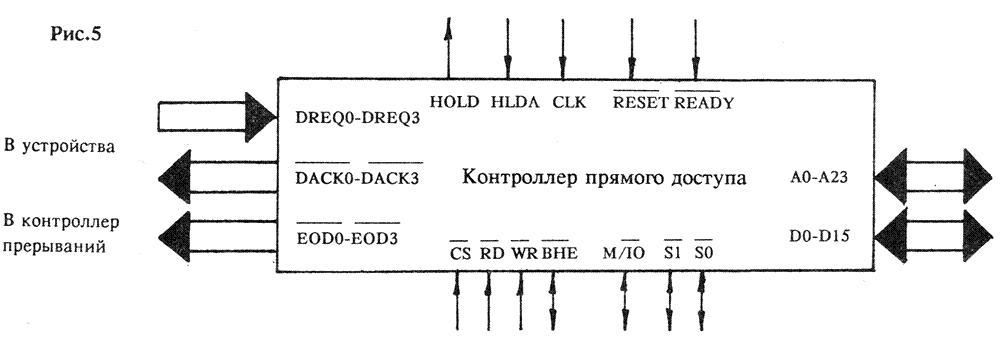
Но для того, чтобы напрямую работать с ОЗУ, внешнее устройство должно взять на себя ряд функций центрального процессора: оно обязано вычислять адреса, генерировать сигналы состояния шины и реагировать на запросы состояния ожидания. Оснащение каждого внешнего устройства соответствующими схемами – затея дорогостоящая, к тому же это может сильно усложнить аппаратную часть компьютера. Разработчики пришли к выводу, что в состав компьютера достаточно включить одно-единственное устройство, отвечающее за реализацию ПДП – контроллер прямого доступа (рис.5). Контроллер прямого доступа, используемый с процессорами Intel – четырехканальный, то есть он способен работать с четырьмя внешними устройствами.
{kind=link}
Давайте посмотрим, каким образом происходит передача управления от ведущего процессора к контроллеру ПДП и как осуществляется прямой диалог между ОЗУ и внешним устройством. Устройство, запрашивающее прямой доступ, посылает ведущему процессору специальный сигнал HOLD, который означает, что оно готово к захвату шины. Процессор, получив сигнал, реагирует так: сначала он завершает цикл шины, а затем, выдав сигнал согласия HLDA, полностью освобождает шину. С этого момента управление шиной передается контроллеру ПДП, который начинает выполнять специальную канальную программу, находящуюся в ОЗУ. Канальная программа состоит из последовательности командных блоков, каждый из которых определяет последующую операцию взаимодействия канала ПДП с ОЗУ. Подключенному к контроллеру устройству остается только передавать свои данные на шину или осуществлять их прием, причем ему неведомо, куда, в какую область памяти попадают его данные или откуда они считываются, так как всем процессом чтения-записи руководит контроллер. Между тем, центральный процессор может производить любые действия, не связанные с обращением к шине. После завершения выполнения канальной программы, контроллер ПДП посылает процессору сигнал прерывания и освобождает шину.
Продолжение в следующей статье
И. Липкин
КомпьютерПресс 3'91